Stock Price Prediction with Time Series Analysis
As you build the movie recommendation system, you will learn how to train algorithms using training data so you can predict the outcome for future datasets. You will also learn about overtraining and techniques to avoid it such as cross-validation. Supervised machine learning relies on patterns to predict values on unlabeled data.
Machine learning algorithm sets XRP price for November 30, 2023 – Finbold – Finance in Bold
Machine learning algorithm sets XRP price for November 30, 2023.
Posted: Mon, 30 Oct 2023 13:37:42 GMT [source]
Machine learning is a powerful tool that can be used to solve a wide range of problems. This makes it possible to build systems that can automatically improve their performance over time by learning from their experiences. For example, if a cell phone company wants to optimize the locations where they build cell phone towers, they can use machine learning to estimate the number of clusters of people relying on their towers.
GPT-4 Opens Its Eyes, Meta’s Generative Facelift, Newsrooms Respond to AI, Beware Training on Generated Data
This ability to learn from experience separates it from more static tools such as business intelligence (BI) and conventional data analytics. Machine learning tends to require structured data and uses traditional algorithms like linear regression. Deep learning employs neural networks and is built to accommodate large volumes of unstructured data. We’ll cover two here just to illustrate some of the ways that data scientists and engineers are going about applying deep learning in the field.
But with Akkio, it’s possible to create compelling models with as little as 100 or 1000 examples. As we’ve explored, if you find that you’re not getting great results with a small dataset, you can always try merging on new data, data augmentation, crowdsourcing platforms, or simply turning to online dataset sources. In this article, we will go over several machine learning algorithms used for solving regression problems. While we won’t cover the math in depth, we will at least briefly touch on the general mathematical form of these models to provide you with a better understanding of the intuition behind these models.
Evolution of machine learning
Third, their complexity makes it difficult to determine whether or why they made a mistake. For those who may not have studied statistics, it can be helpful to first define correlation and regression, as they are commonly used techniques for investigating the relationship among quantitative variables. Correlation is a measure of association between two variables that are not designated as either dependent or independent. Regression at a basic level is used to examine the relationship between one dependent and one independent variable. Because regression statistics can be used to anticipate the dependent variable when the independent variable is known, regression enables prediction capabilities.
Through intellectual rigor and experiential learning, this full-time, two-year MBA program develops leaders who make a difference in the world. Even after the ML model is in production and continuously monitored, the job continues. Business requirements, technology capabilities and real-world data change in unexpected ways, potentially giving rise to new demands and requirements. Since there isn’t significant legislation to regulate AI practices, there is no real enforcement mechanism to ensure that ethical AI is practiced. The current incentives for companies to be ethical are the negative repercussions of an unethical AI system on the bottom line.
Shortcomings of Visualizations for Human-in-the-Loop Machine … – Stanford HAI
Shortcomings of Visualizations for Human-in-the-Loop Machine ….
Posted: Mon, 09 Oct 2023 07:00:00 GMT [source]
Essentially, these machine learning tools are fed millions of data points, and they configure them in ways that help researchers view what compounds are successful and what aren’t. Instead of spending millions of human hours on each trial, machine learning technologies can produce successful drug compounds in weeks or months. Trading firms are using machine learning to amass a huge lake of data and determine the optimal price points to execute trades. These complex high-frequency trading algorithms take thousands, if not millions, of financial data points into account to buy and sell shares at the right moment. The financial services industry is championing machine learning for its unique ability to speed up processes with a high rate of accuracy and success.
Data Versioning
Association or frequent pattern mining finds frequent co-occurring associations (relationships, dependencies) in large sets of data items. An example of co-occurring associations is products that are often purchased together, such as the famous beer and diaper story. An analysis of behavior of grocery shoppers discovered that men who buy diapers often also buy beer. The benefits of predictive maintenance extend to inventory control and management. Avoiding unplanned equipment downtime by implementing predictive maintenance helps organizations more accurately predict the need for spare parts and repairs—significantly reducing capital and operating expenses. Successful marketing has always been about offering the right product to the right person at the right time.
Early in 2018, Google expanded its machine-learning driven services to the world of advertising, releasing a suite of tools for making more effective ads, both digital and physical. In 2020, OpenAI’s GPT-3 (Generative Pre-trained Transformer 3) made headlines for its ability to write like a human, about almost any topic you could think of. At each step of the training process, the vertical distance of each of these points from the line is measured. If a change in slope or position of the line results in the distance to these points increasing, then the slope or position of the line is changed in the opposite direction, and a new measurement is taken.
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
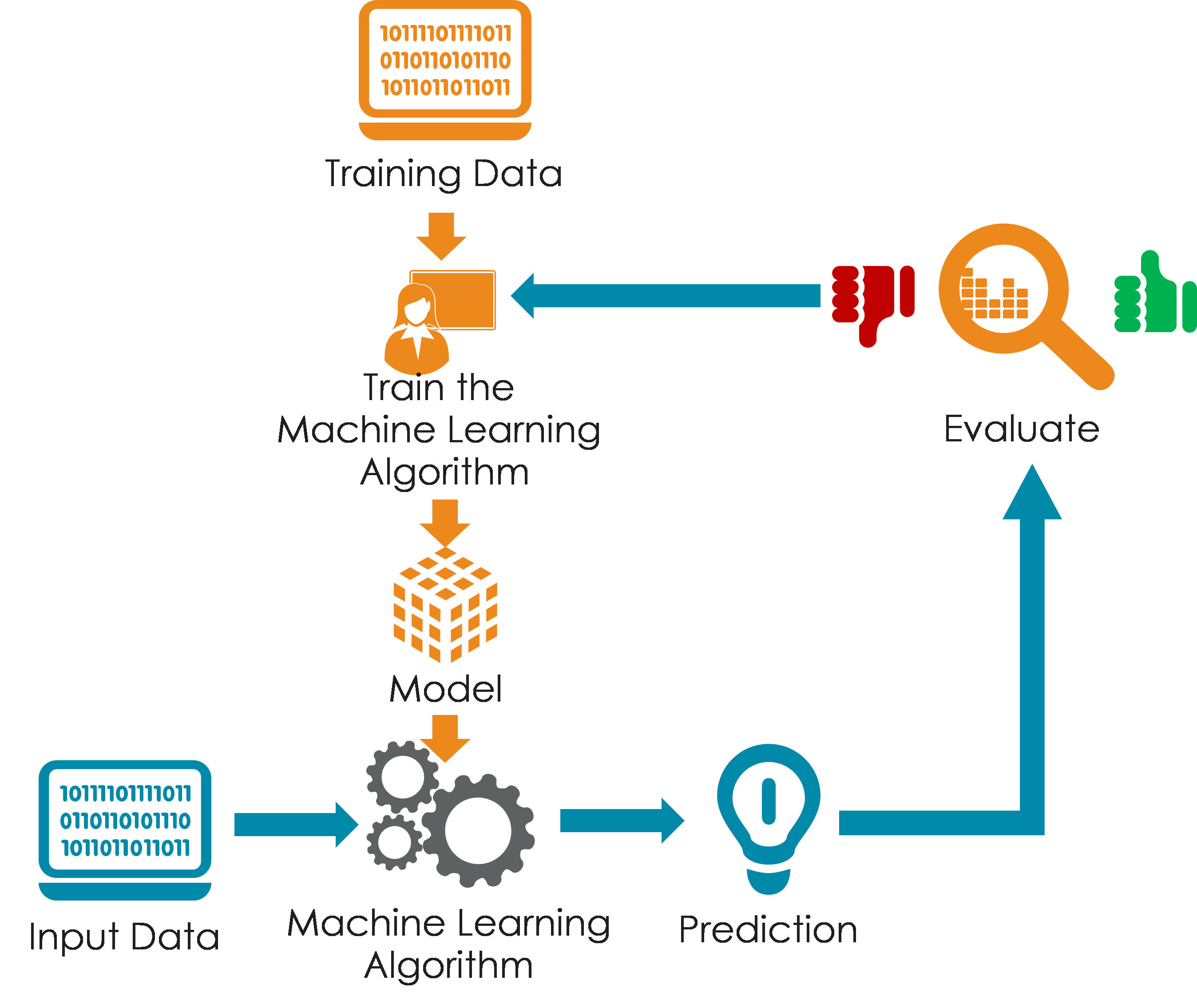
The input data goes through the Machine Learning algorithm and is used to train the model. Once the model is trained based on the known data, you can use unknown data into the model and get a new response. It was a little later, in the 1950s and 1960s, when different scientists started to investigate how to apply the human brain neural network’s biology to attempt to create the first smart machines.
Differentiable Image Parameterizations
Explore more about this machine learning (ML) Project- Build a plant species identification algorithm to know about the implementation of this project from scratch. You will enjoy getting to know about the methods that include image-based features. And, as you may have guessed already, this would be a machine learning classification project, so you will be introduced to the implementation of classification machine learning algorithms in great depth.
Additional forks will add new information that can increase a tree’s prediction accuracy. At the best split, the results of each branch should be as homogeneous (or pure) as possible. There are several mathematical methods you can choose between to calculate the best split. However, a split point meant to capture every San Francisco home will include many New York homes as well.
As a result, the binary systems modern computing is based on can be applied to complex, nuanced things. Scikit-learn is a popular Python library and a great option for those who are just starting out with machine learning. You can use this library for tasks such as classification, clustering, and regression, among others. Watson Studio is great for data preparation and analysis and can be customized to almost any field, and their Natural Language Classifier makes building advanced SaaS analysis models easy. For example, they can learn to recognize stop signs, identify intersections, and make decisions based on what they see. For example, facial recognition technology is being used as a form of identification, from unlocking phones to making payments.